



Algorithms 2024, 17(4), 161; https://doi.org/10.3390/a17040161 - 18 Apr 2024
Abstract
Enhancing lung cancer diagnosis requires precise early detection methods. This study introduces an automated diagnostic system leveraging computed tomography (CT) scans for early lung cancer identification. The main approach is the integration of three distinct feature analyses: the novel 3D-Local Octal Pattern (LOP)
[...] Read more.
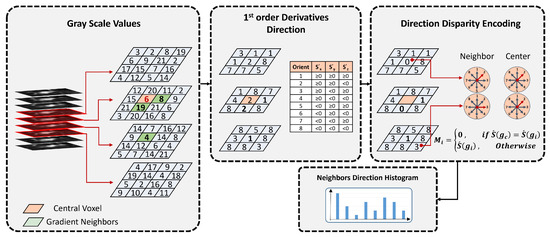
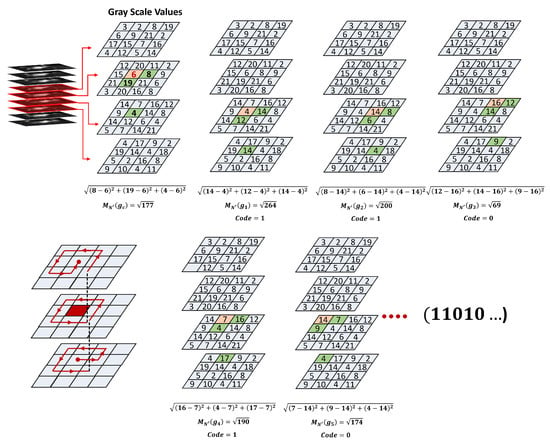
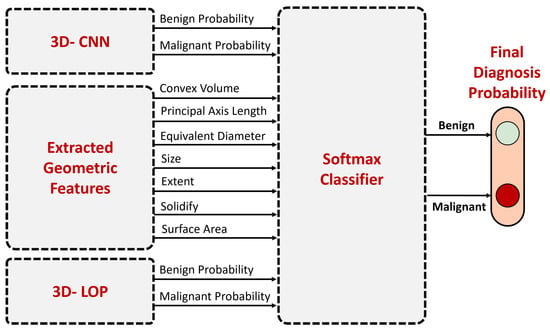
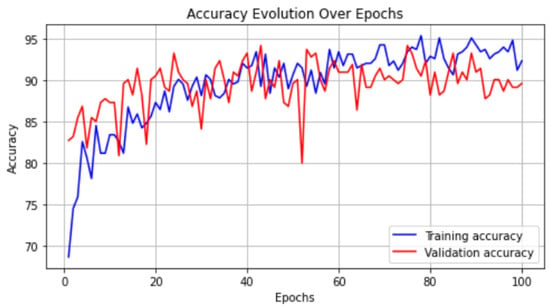
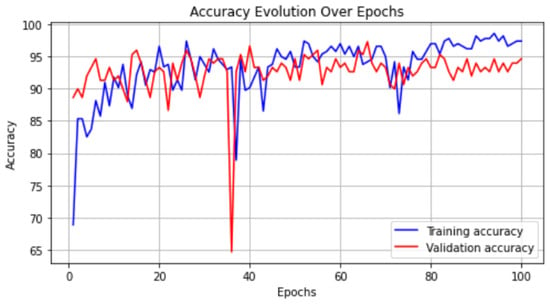
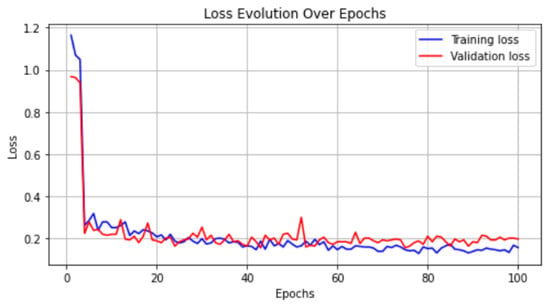
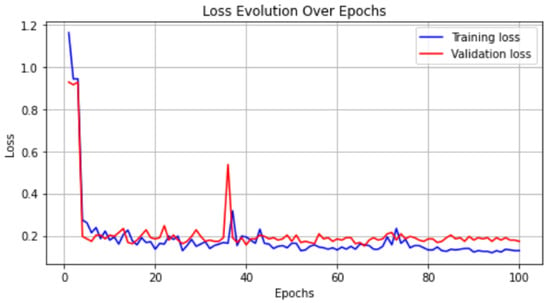
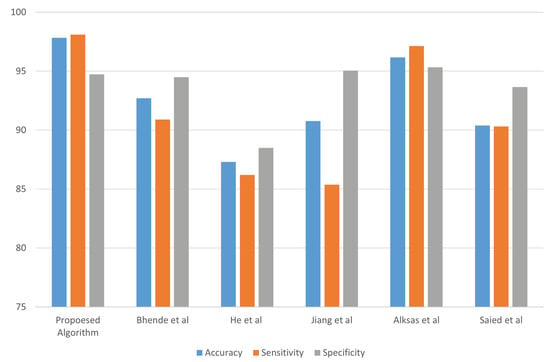
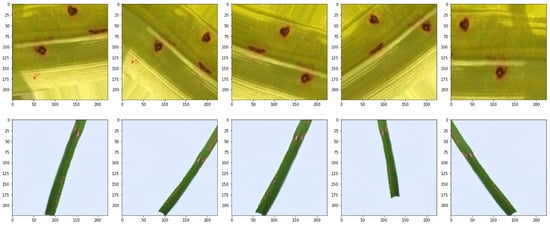
Enhancing lung cancer diagnosis requires precise early detection methods. This study introduces an automated diagnostic system leveraging computed tomography (CT) scans for early lung cancer identification. The main approach is the integration of three distinct feature analyses: the novel 3D-Local Octal Pattern (LOP) descriptor for texture analysis, the 3D-Convolutional Neural Network (CNN) for extracting deep features, and geometric feature analysis to characterize pulmonary nodules. The 3D-LOP method innovatively captures nodule texture by analyzing the orientation and magnitude of voxel relationships, enabling the distinction of discriminative features. Simultaneously, the 3D-CNN extracts deep features from raw CT scans, providing comprehensive insights into nodule characteristics. Geometric features and assessing nodule shape further augment this analysis, offering a holistic view of potential malignancies. By amalgamating these analyses, our system employs a probability-based linear classifier to deliver a final diagnostic output. Validated on 822 Lung Image Database Consortium (LIDC) cases, the system’s performance was exceptional, with measures of
(This article belongs to the Special Issue Algorithms for Computer Aided Diagnosis)
►
Show Figures
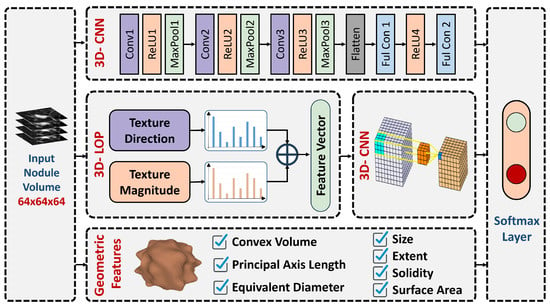
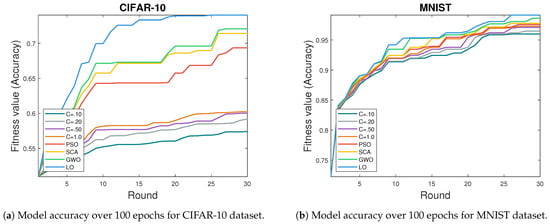
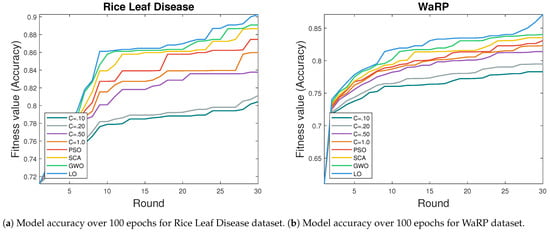
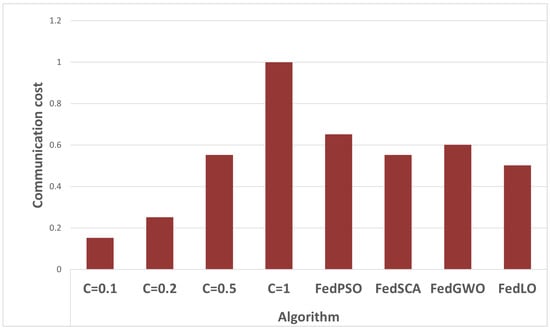
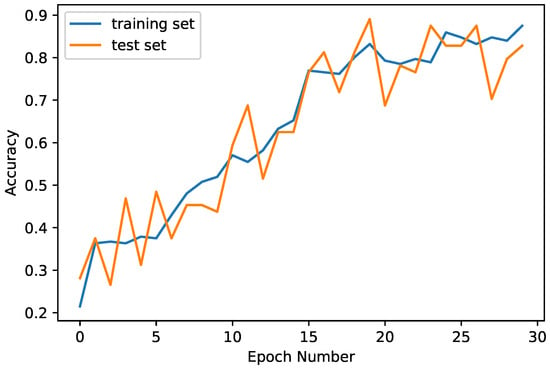
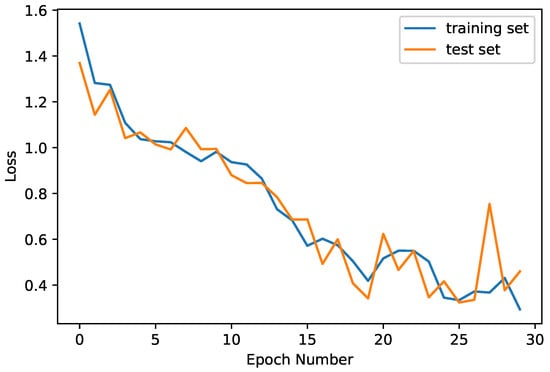
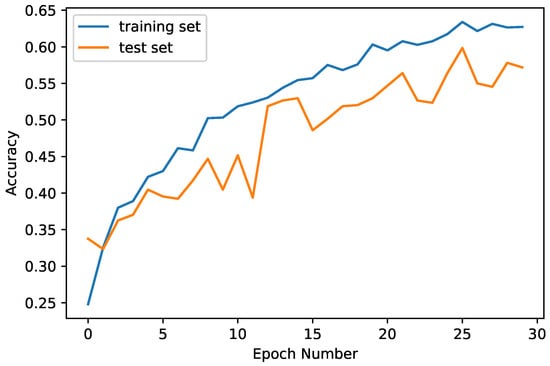
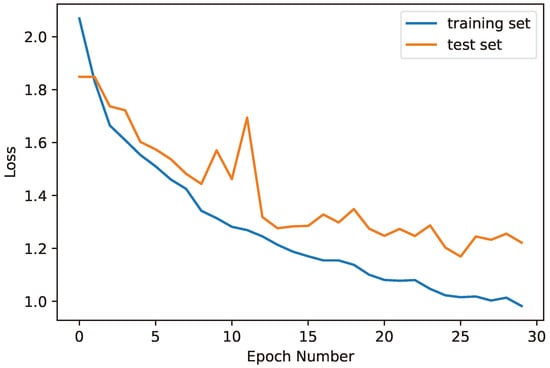
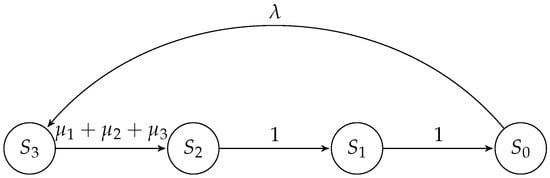
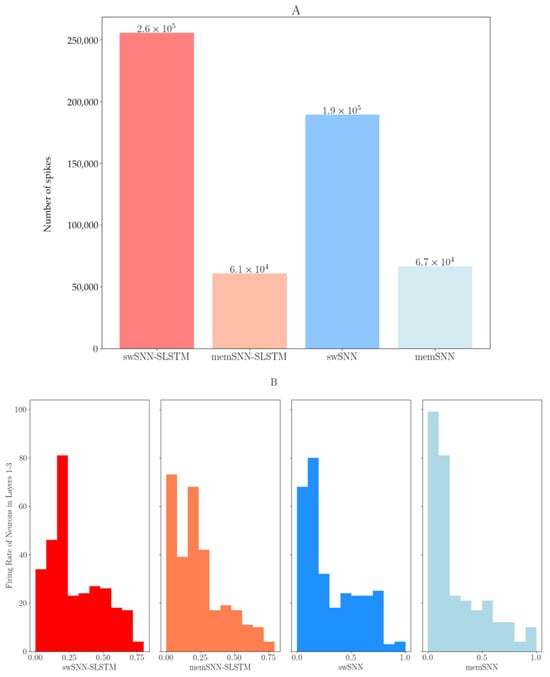
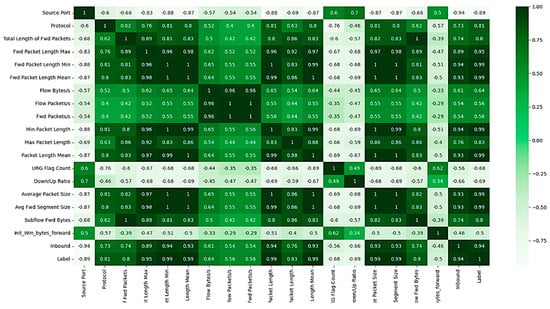
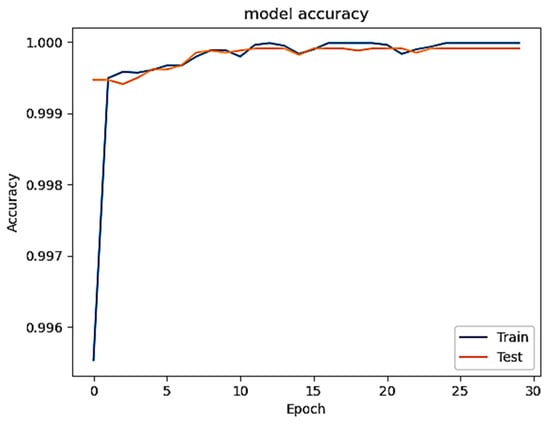
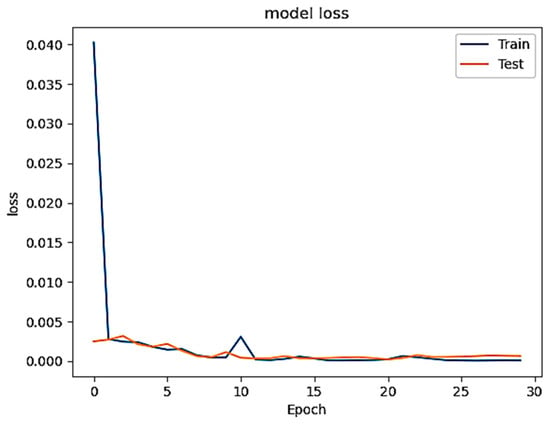
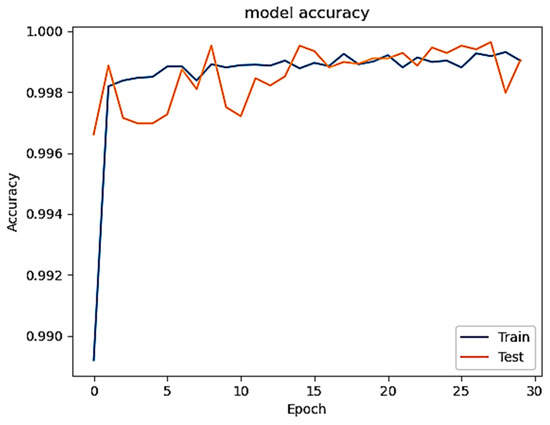
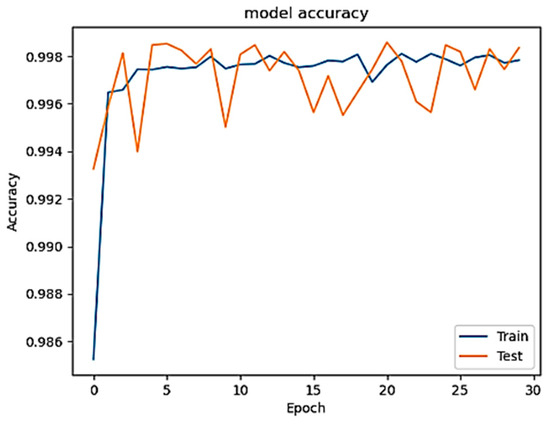
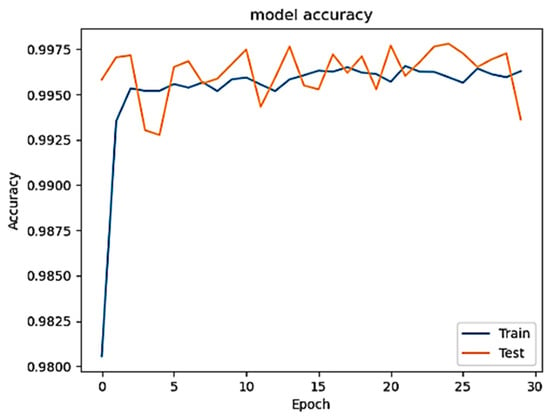
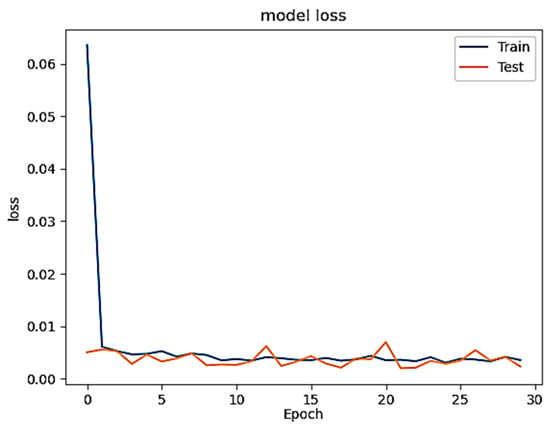
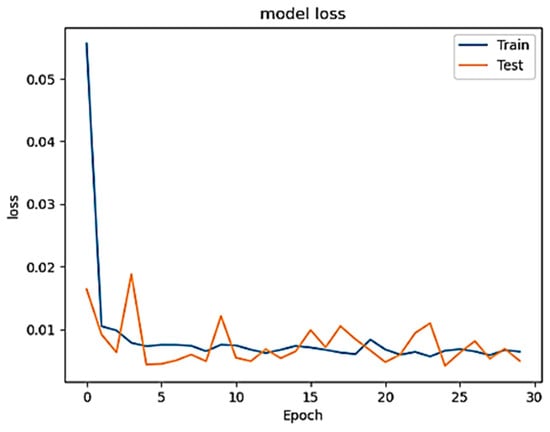
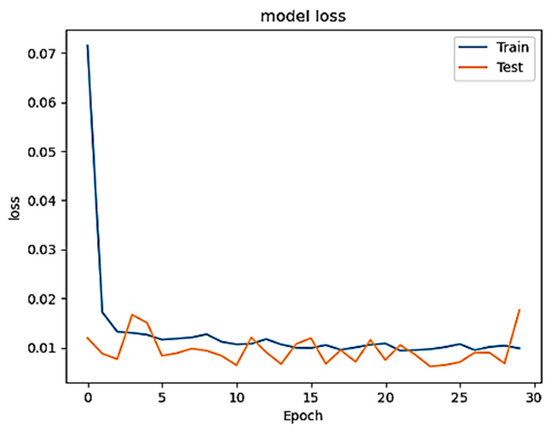
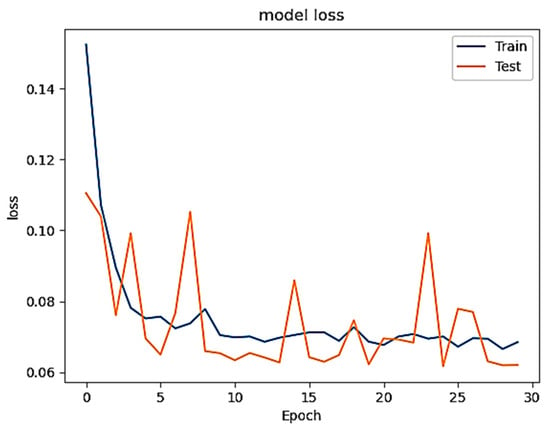
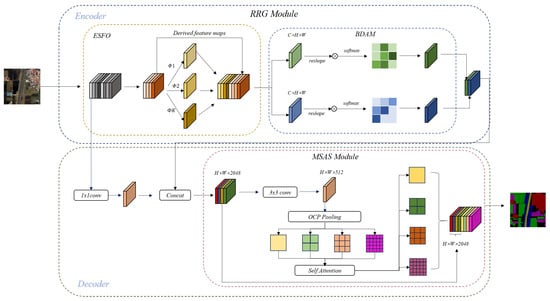
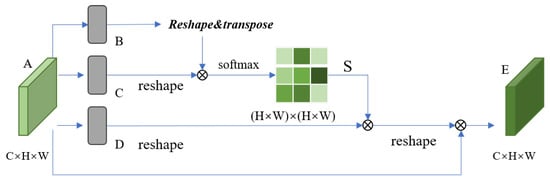
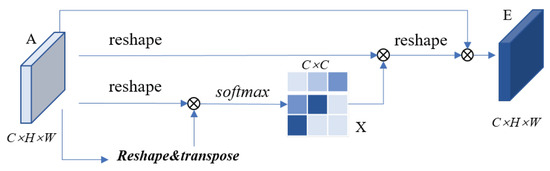
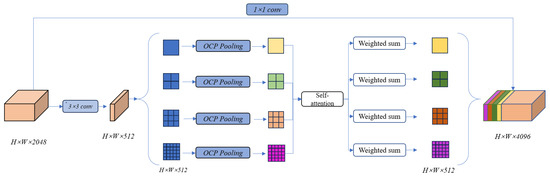
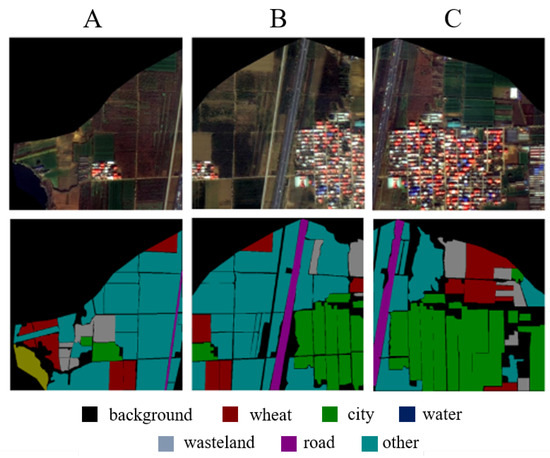
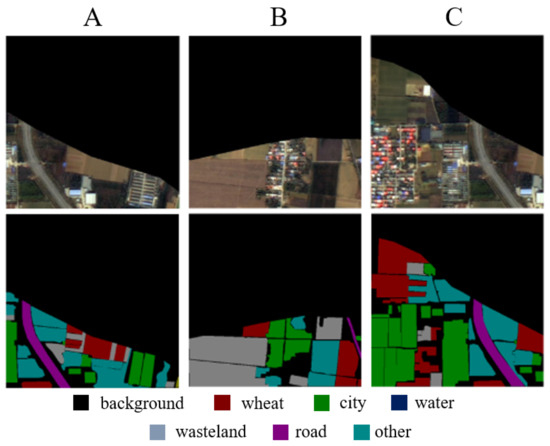
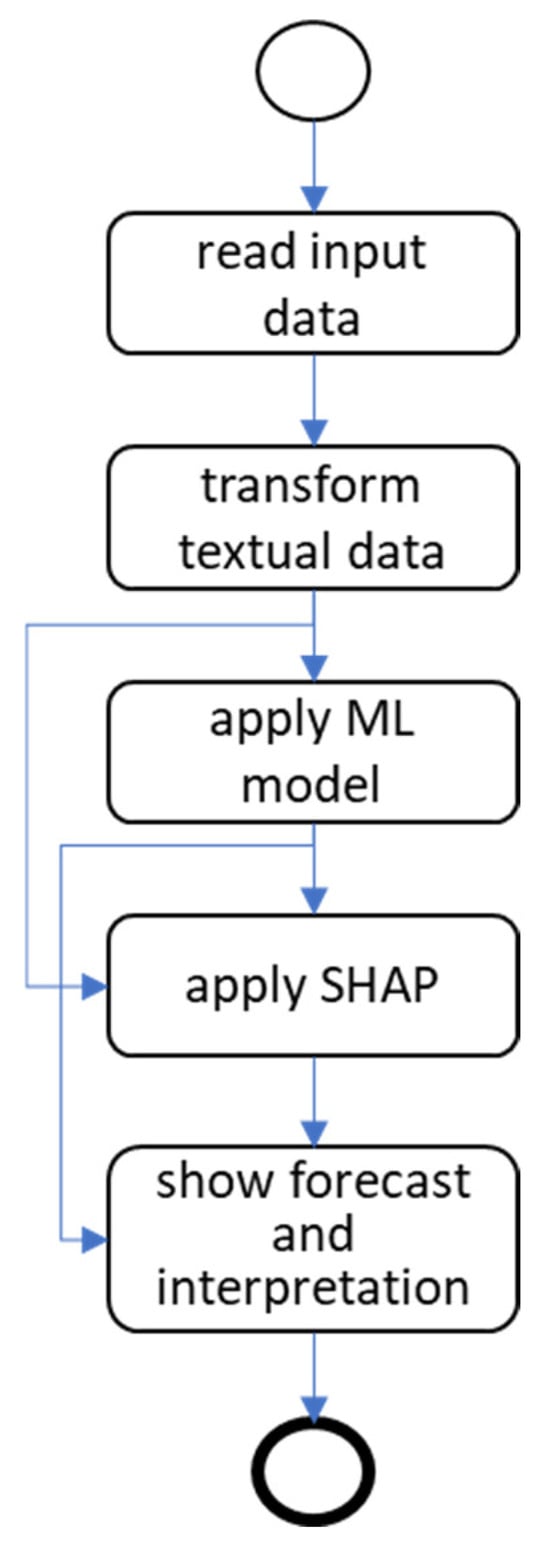
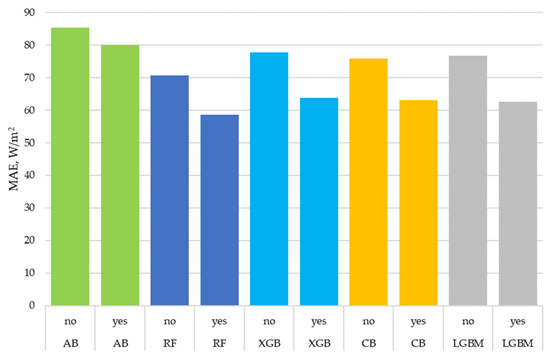
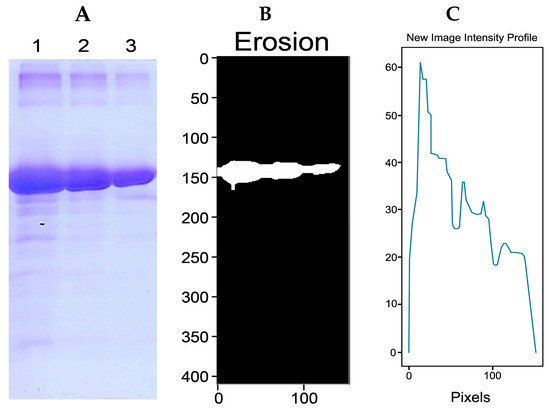
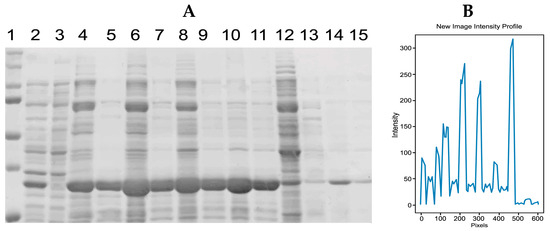
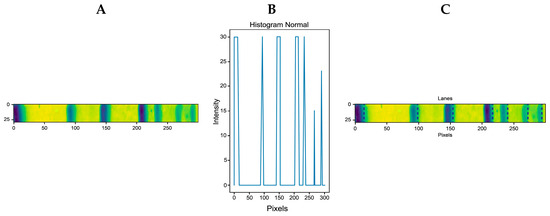
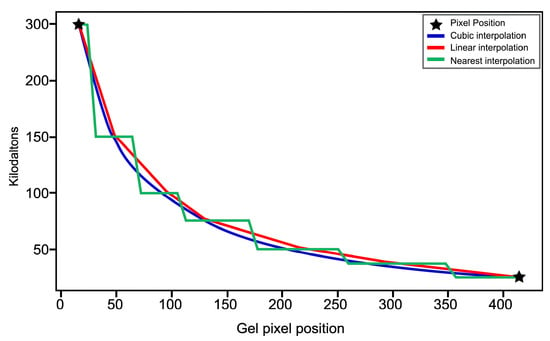
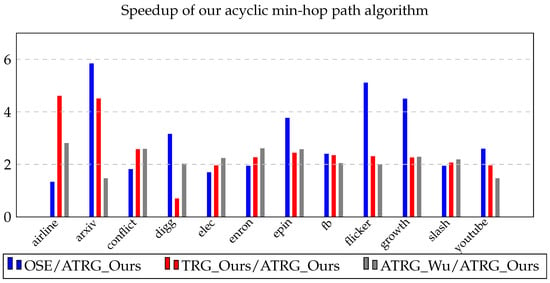
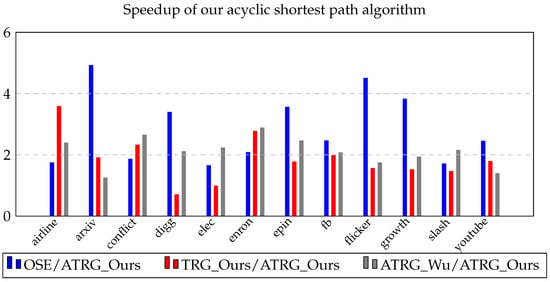
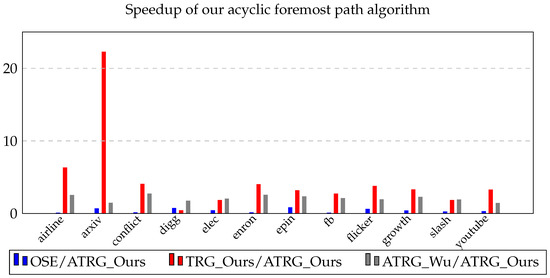
Figure 1
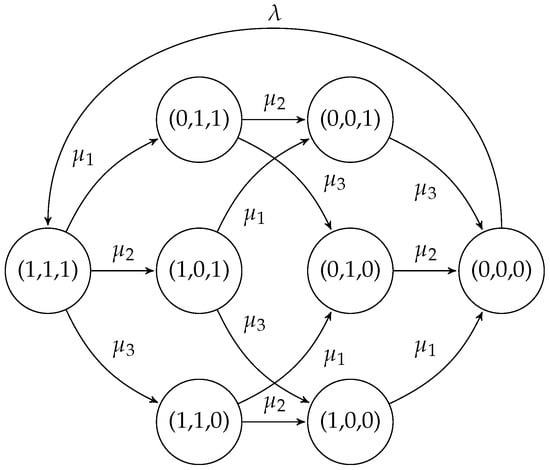
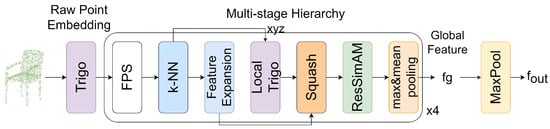
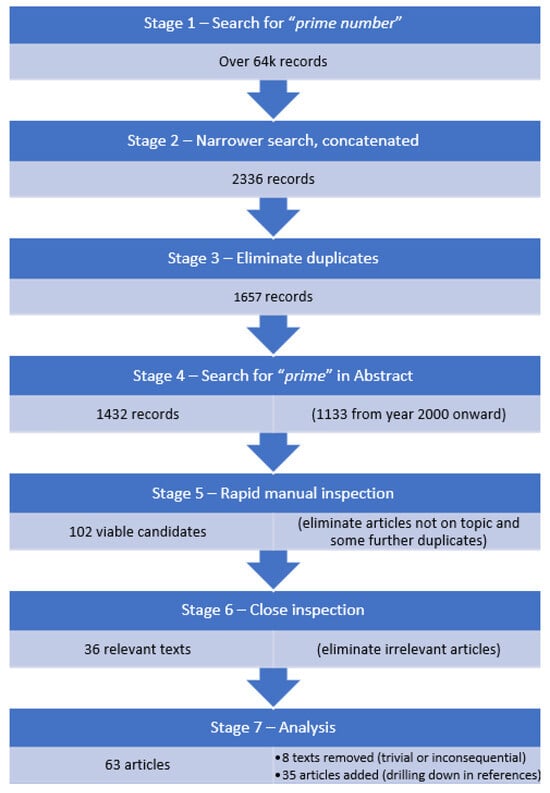
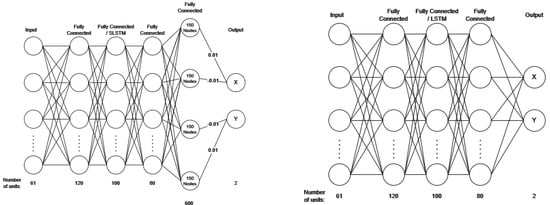
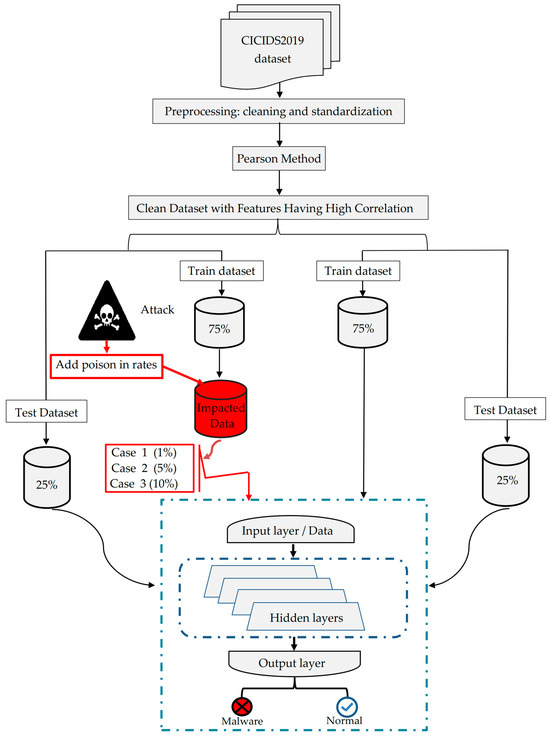

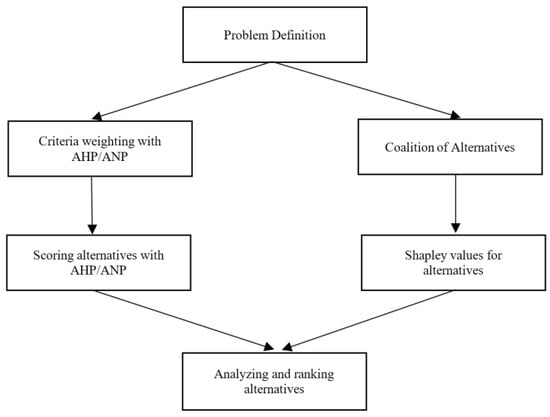
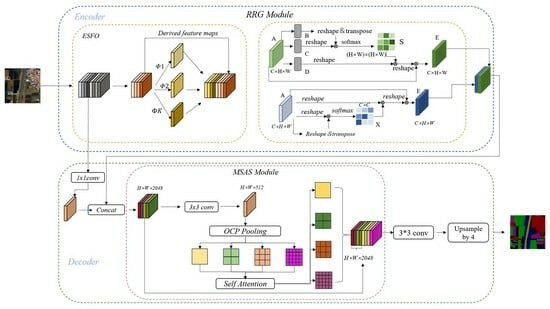
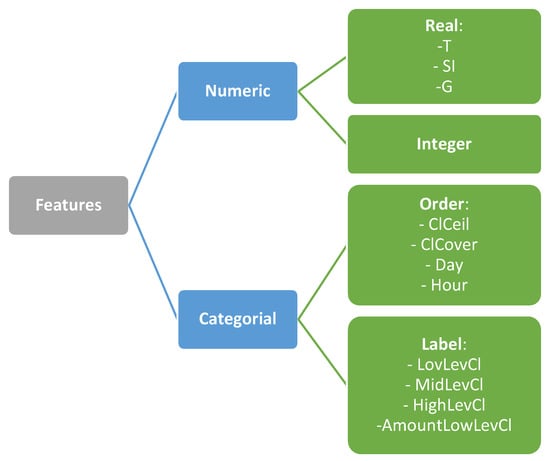







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}