






J. Imaging 2024, 10(4), 94; https://doi.org/10.3390/jimaging10040094 - 17 Apr 2024
Abstract
Apple cultivar classification is challenging due to the inter-class similarity and high intra-class variations. Human experts do not rely on single-view features but rather study each viewpoint of the apple to identify a cultivar, paying close attention to various details. Following our previous
[...] Read more.
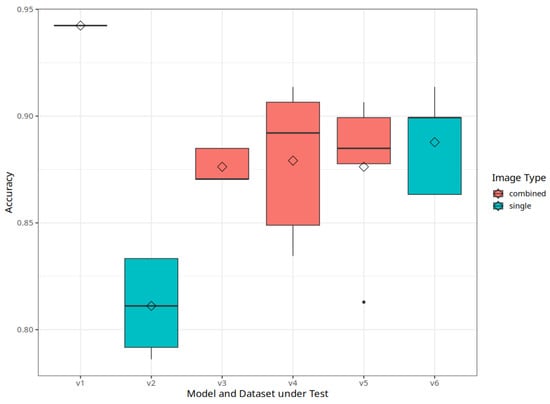
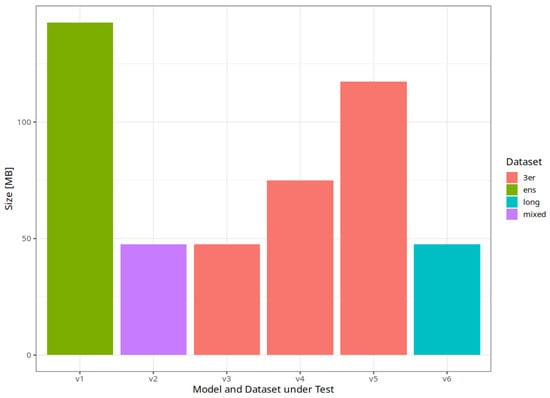
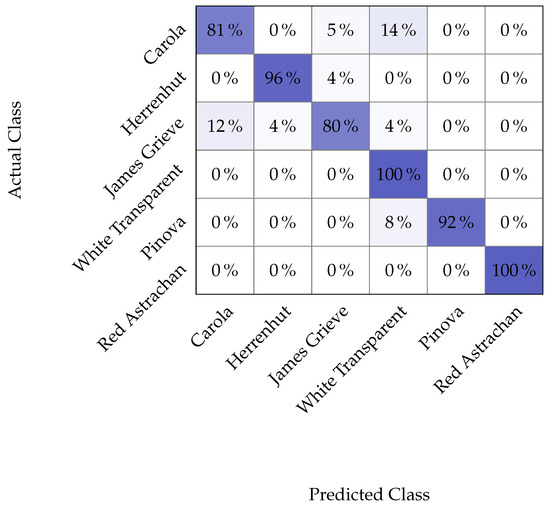
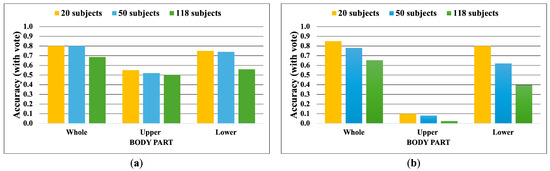
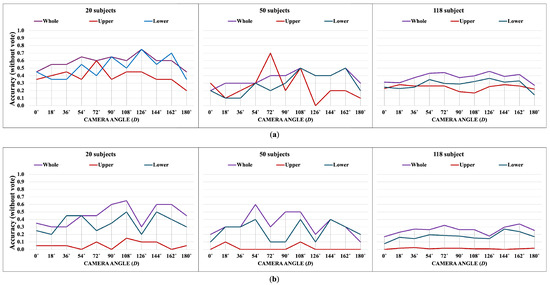
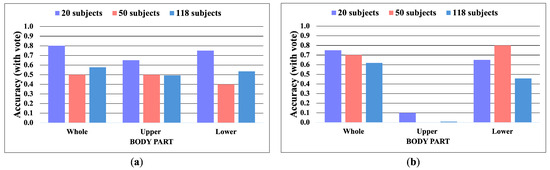
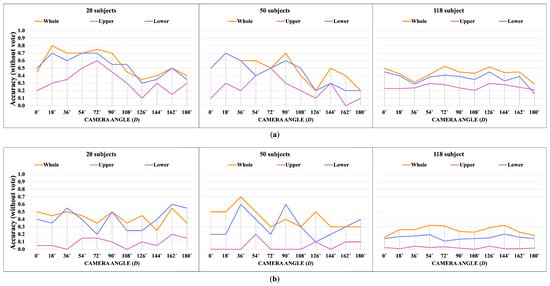
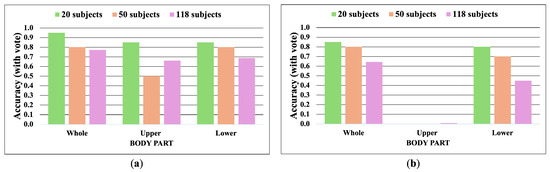
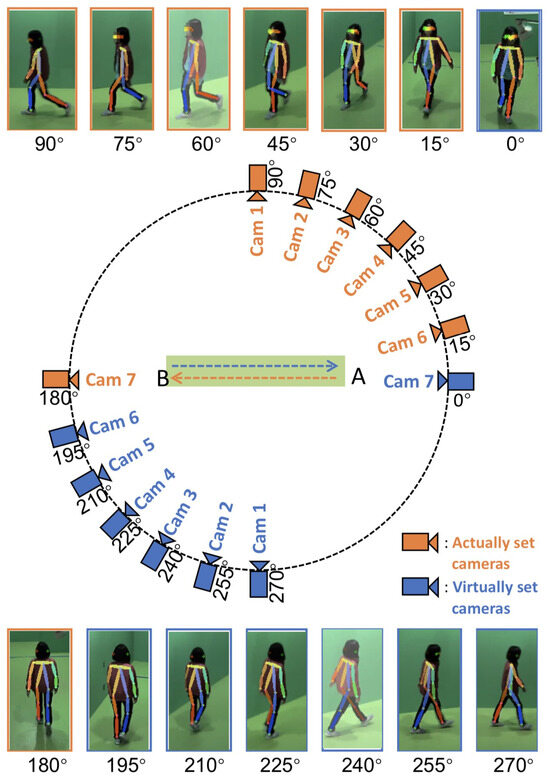
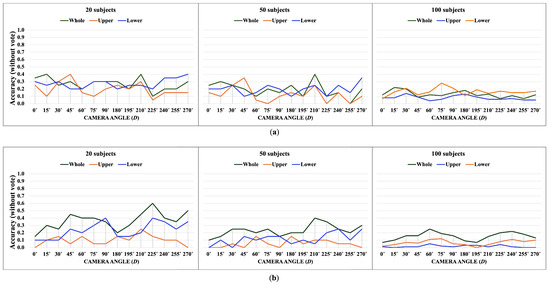
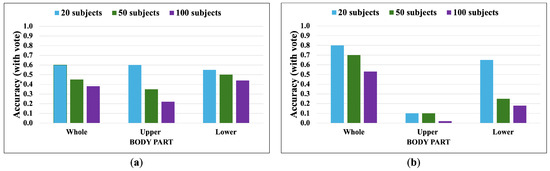
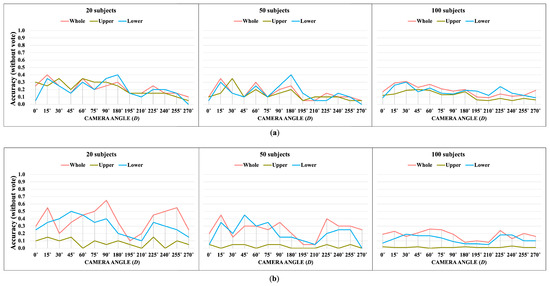
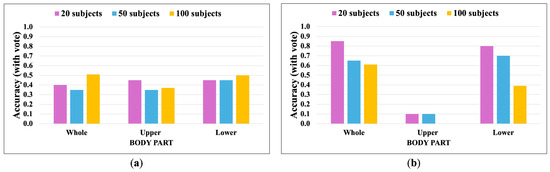
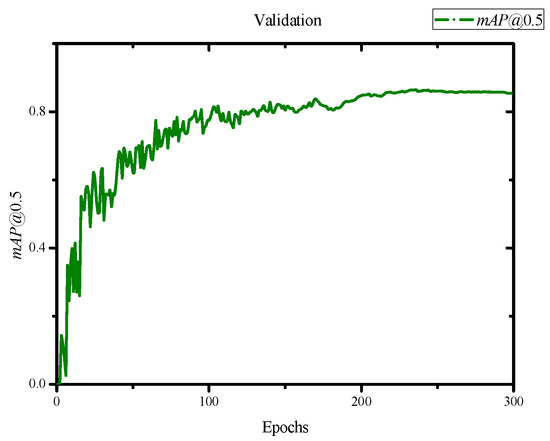
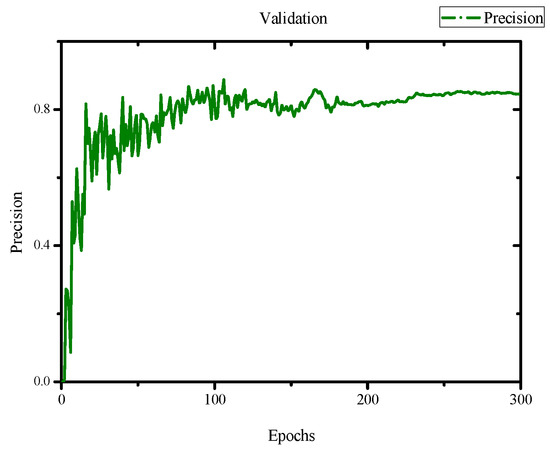
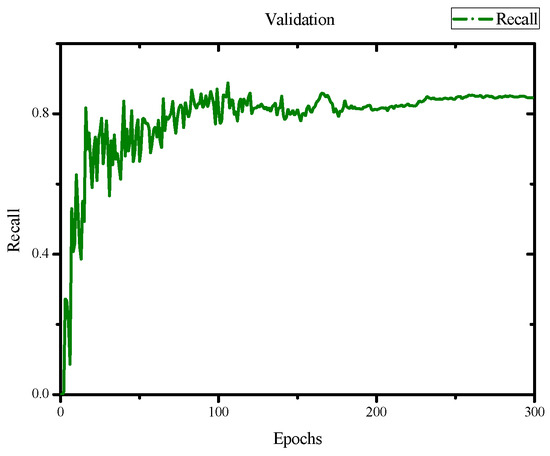
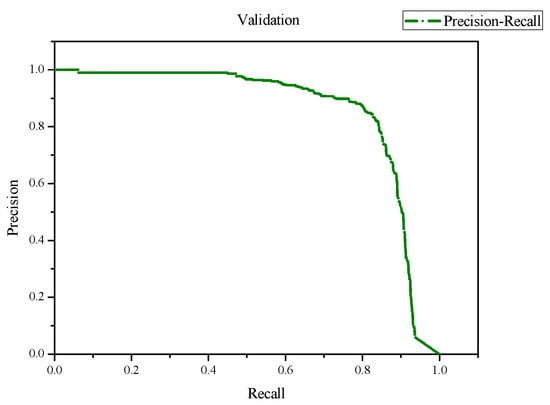
Apple cultivar classification is challenging due to the inter-class similarity and high intra-class variations. Human experts do not rely on single-view features but rather study each viewpoint of the apple to identify a cultivar, paying close attention to various details. Following our previous work, we try to establish a similar multiview approach for machine-learning (ML)-based apple classification in this paper. In our previous work, we studied apple classification using one single view. While these results were promising, it also became clear that one view alone might not contain enough information in the case of many classes or cultivars. Therefore, exploring multiview classification for this task is the next logical step. Multiview classification is nothing new, and we use state-of-the-art approaches as a base. Our goal is to find the best approach for the specific apple classification task and study what is achievable with the given methods towards our future goal of applying this on a mobile device without the need for internet connectivity. In this study, we compare an ensemble model with two cases where we use single networks: one without view specialization trained on all available images without view assignment and one where we combine the separate views into a single image of one specific instance. The two latter options reflect dataset organization and preprocessing to allow the use of smaller models in terms of stored weights and number of operations than an ensemble model. We compare the different approaches based on our custom apple cultivar dataset. The results show that the state-of-the-art ensemble provides the best result. However, using images with combined views shows a decrease in accuracy by 3% while requiring only 60% of the memory for weights. Thus, simpler approaches with enhanced preprocessing can open a trade-off for classification tasks on mobile devices.
Full article
(This article belongs to the Special Issue Computer Vision and Deep Learning: Trends and Applications (2nd Edition))
►
Show Figures

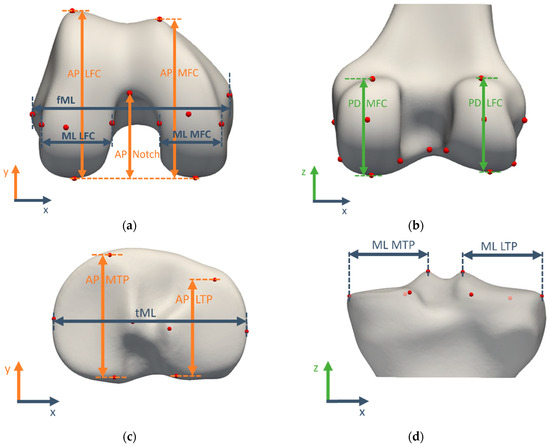
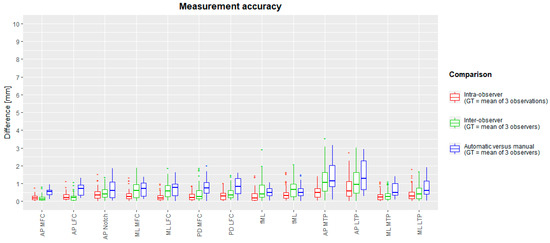
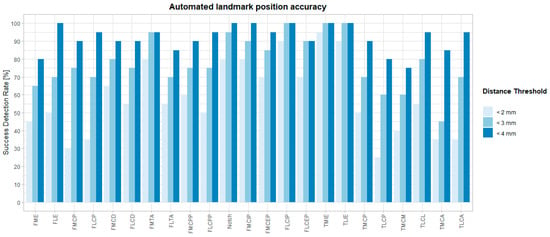
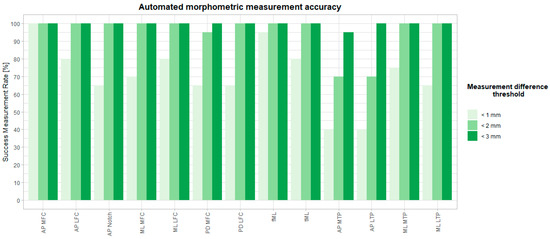
Figure 1

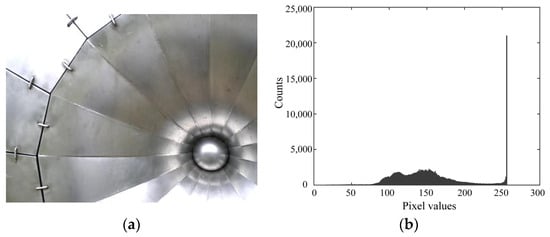
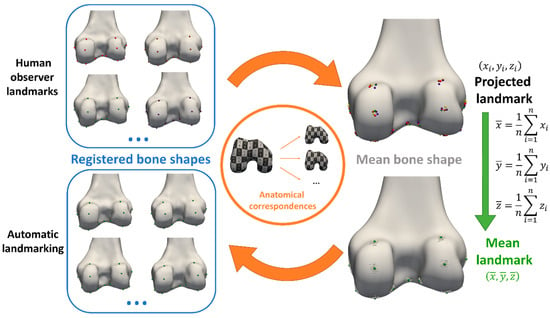

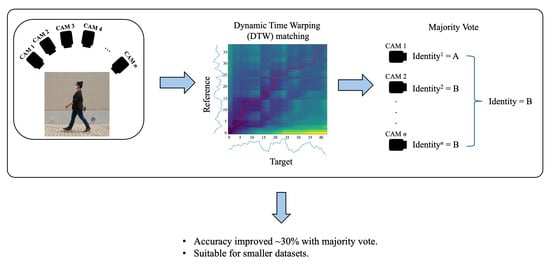










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}